---
title: "MATH 80667A - Week 2"
author: "Léo Belzile"
format: html
eval: true
echo: true
message: false
warning: false
code-tools:
source: true
toggle: false
caption: "Download Quarto file"
---
```{r}
#| echo: false
options(scipen = 100, digits = 3)
```
```{r}
#| label: tbl-summary-stats-arithmetic
#| tbl-cap: "Summary statistics (mean and standard deviation) of arithmetic scores per experimental group."
library(hecedsm)
library(dplyr) # data manipulation
library(knitr) # data formatting
library(ggplot2) # grammar of graphics
library(emmeans) # marginal means and contrasts
# Load arithmetic data
data(arithmetic, package = "hecedsm")
# categorical variable = factor
str(arithmetic) # Look up data
# Compute summary statistics
summary_stat <-
arithmetic |>
group_by(group) |>
summarize(mean = mean(score),
sd = sd(score))
# Create HTML table
knitr::kable(summary_stat,
digits = 2)
```
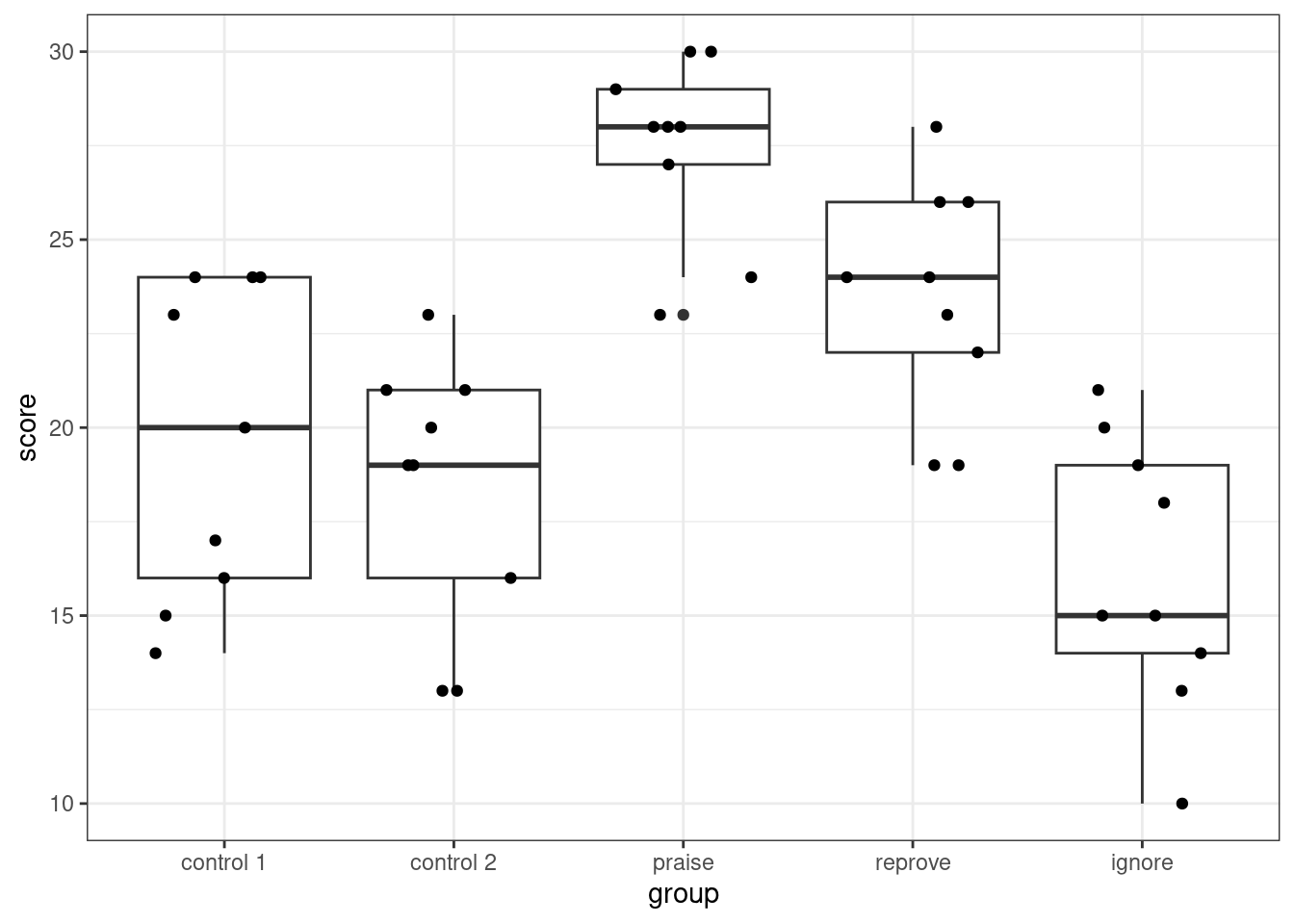
```{r}
#| label: fig-boxplot-arithmetic
#| fig-cap: "Box and whisker plot with jittered data of arithmetic exam score per experimental group."
# Boxplot with jittered data
ggplot(data = arithmetic,
aes(x = group,
y = score)) +
geom_boxplot() + # box and whiskers plot
# scatterplot, with horizontal jittering
geom_jitter(width = 0.3,
height = 0) +
theme_bw()
```
```{r}
#| label: tbl-pairwise-diff
#| tbl-cap: "Pairwise differences for praise vs reprove for the `arithmetic` data."
# Analysis of variance model - global test of equality of means
model <- lm(score ~ group, data = arithmetic)
# Compute mean for each group with pooled standard error
margmeans <- emmeans(model, specs = "group")
# Compute pairwise differences
contrast(margmeans,
method = "pairwise",
adjust = 'none',
infer = TRUE) |>
as_tibble() |> # transform to data frame
filter(contrast == "praise - reprove") |>
# extract the sole pairwise difference
knitr::kable(digits = 3)
```
```{r}
# Manual calculation of p-value
2*pt(q = 2.467, df = 45 - 5, lower.tail = FALSE)
# Manual calculation of confidence intervals
df <- model$df.residual # degrees of freedom
sigma <- summary(model)$sigma # standard deviation
se_diff <- sqrt(sigma^2/9 + sigma^2/9) # Standard error of difference in mean
# Difference between praise and reprove means
delta <- diff(predict(model, newdata = data.frame(group = c("reprove", "praise"))))
(ci <- delta + qt(c(0.025,0.975), df = df) * se_diff)
```